
About Natural Learning
Natural learning mimics the brain's quick categorization ability, called prototype-based learning. It's highly interpretable and diverges from traditional machine learning by focusing on core features of two single ideal prototypes rather than selecting features for all samples. This leads to significant sparsity gains in both sample and feature dimensions.

The Sparsest Machine Learning Model
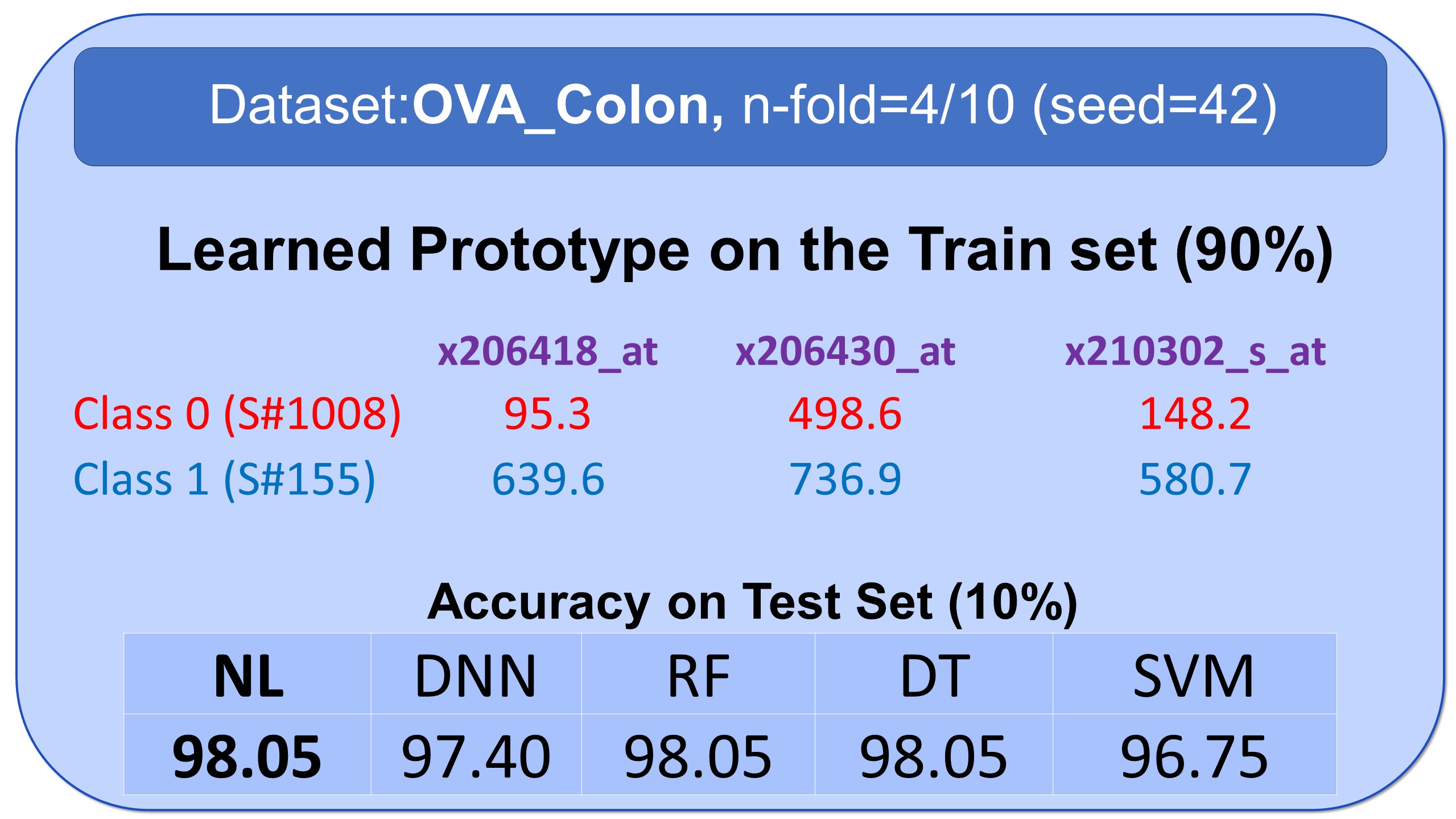
Natural Learning stands as the sole algorithm capable of uncovering sparse prototypes across both sample and feature dimensions concurrently. In this example, NL effectively pinpoints two prototype patients, one from colon cancer and one from its counterpart class, while highlighting only three crucial genes that define these prototypes. No other machine learning algorithm can achieve such remarkable performance in identifying a compact subspace within the training set, endowed with such potent discriminatory capacity. Click on the "Demo" menu for more examples.

The Highest Prediction Speed
Natural Learning advances the frontier of state-of-the-art regarding prediction time due to its very small model size: 1/5 of Decision Trees, and 1/10 of DNN. This gives natural learning a distinct position in real-time applications (e.g., defense, security systems, online-trading) and embedded systems (e.g., wearable devices).

Hyperparameter-Free and Parameter-Free
Natural Learning is unique comparing other classifiers. It doesn't estimate any weights (model parameters) or learn any rules. Also, despite being hyperparameter-free, it does not memorize the entire training set! NL stores only one sparse prototype from each class!

The Most Interpretable Model
We assess pruned trees and random forest alongside the sparse features of logistic regression, comparing them to the ratio of prototype features identified by Natural Learning. Natural Learning offers interpretability that surpasses that of Decision Trees by threefold, and exceeds that of Random Forest and Logistic Regression by fourfold.

The Most Explainable Model
In binary classification, Natural Learning finds exactly two samples as support vectors, which is 1% of linear SVM. SVM with RBF Kernel finds almost all samples as support vectors.

Similarity to Deep Learning
We compared the similairty of NL predictions to other classifiers based on 160k predictions they made on 170 training sets. Deep Neural Networks found to be best match with NL in terms of behaviour on predictions, with 5.65% mismatch in their predictions! The least similar classifer was logistic regression.

The Lowest Variance
Natural Learning has a surprising property in bias-variance trade-off. It has the lowest variance among all classifiers, even lower than deep nerual networks (0.018 vs. 0.029). It seems that Natural Learning is oposite equivalant of nearest neighbor (zero bias).

Natural Learning vs. Black-Box Models
Across 170 training sets, we evaluated the instances where the test prediction accuracy of Natural Learning matched or exceeded that of two prominent black-box models: Random Forest (RF) and Deep Neural Networks (DNN), as well as linear SVM. Does the marginal difference justify opting for a black-box model? While there may be a 10% more loosing ratio, the substantial advantages in interpretability, explainability, simplicity, generalizability, and prediction speed are regained.
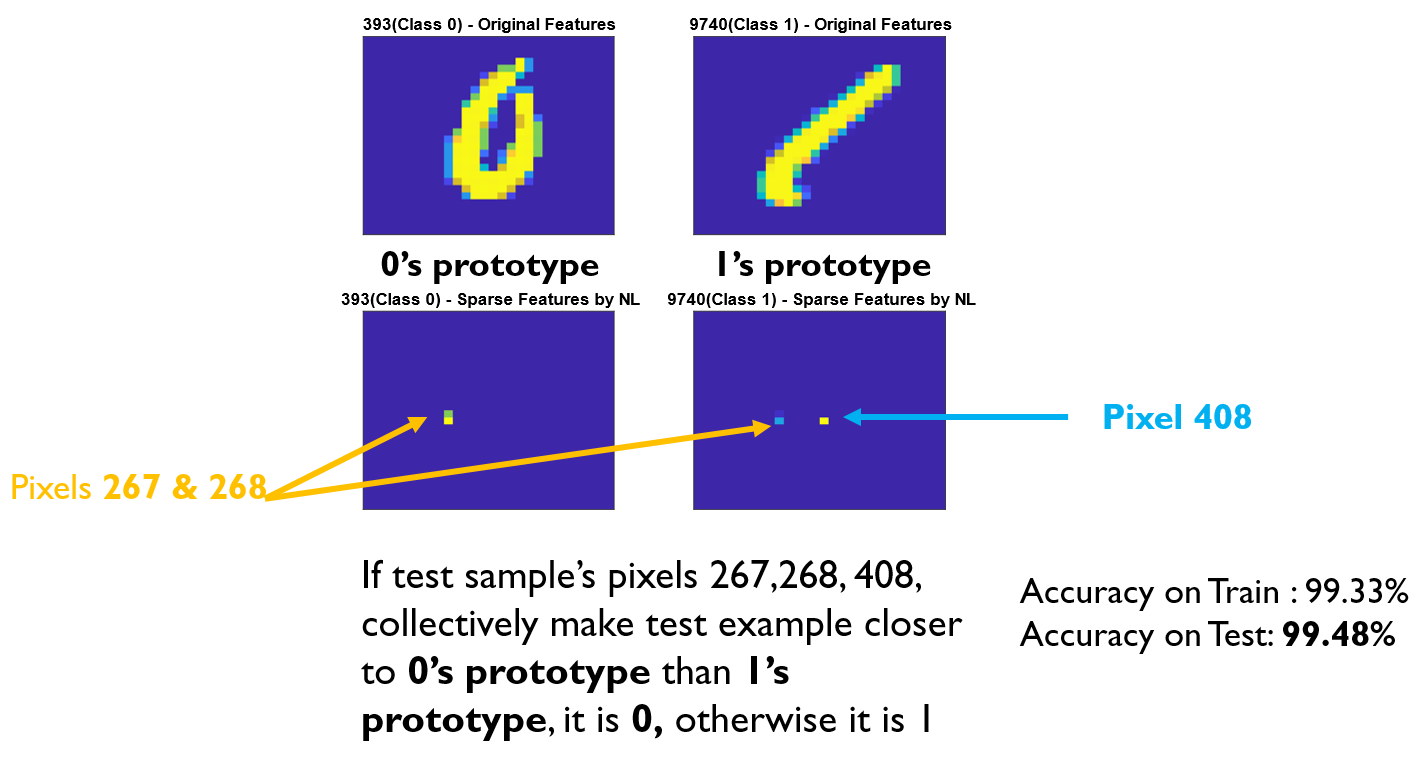
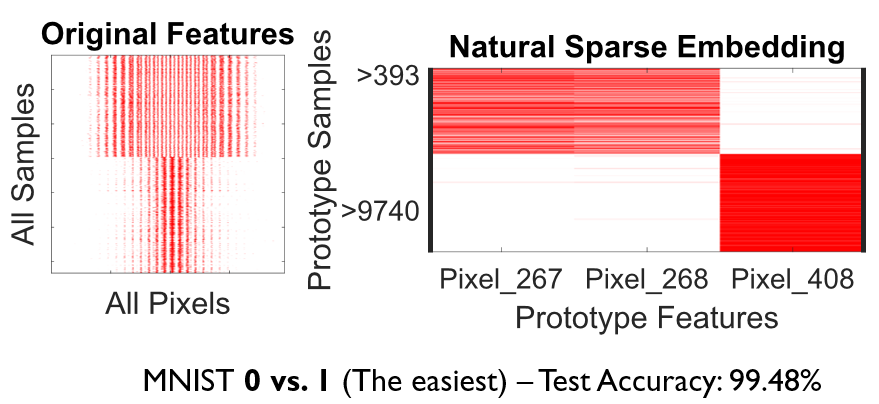
MNIST dataset (0 vs. 1): only 3 pixels and 2 samples are enough for 99.48% test accuracy!
In the MNIST dataset, specifically distinguishing between the digits 0 and 1, the utilization of only three pixels (267, 268, and 408) from two samples (393 and 9740) yields a remarkable test accuracy of 99.48%. Essentially, this implies that the remaining portion of the training set is unnecessary; solely these pixels from these two samples are sufficient for achieving such high predictive accuracy.
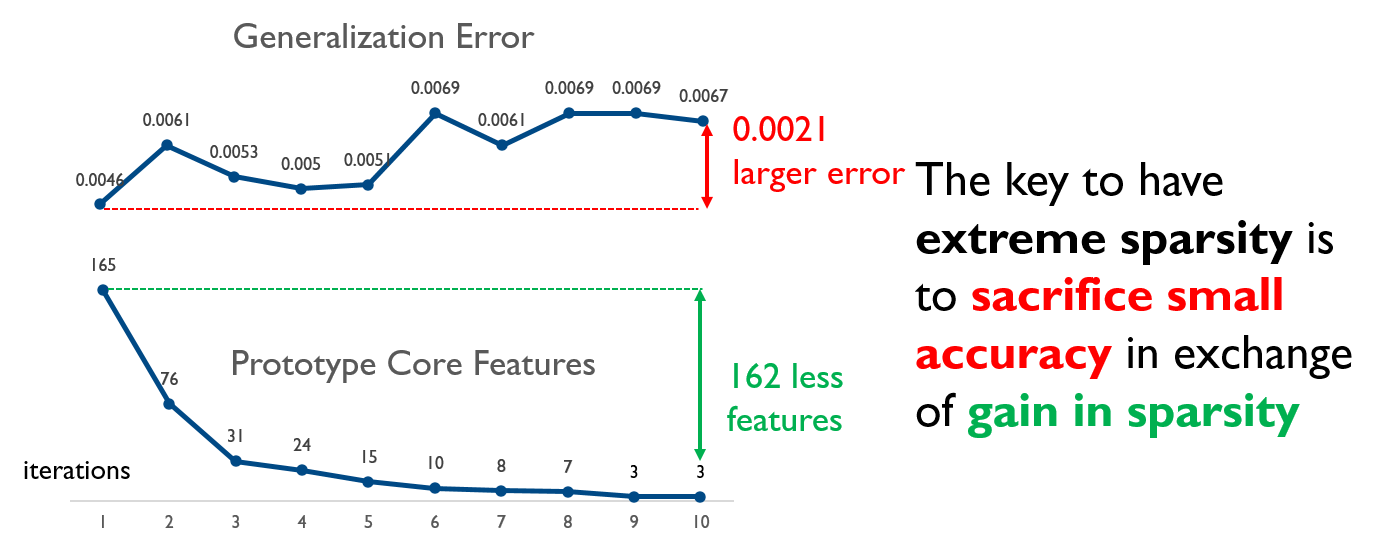
Extreme Sparsity in Exchange of Small Accuracy Loss
The key to have extreme sparsity is to sacrifice small accuracy in exchange of gain in sparsity.
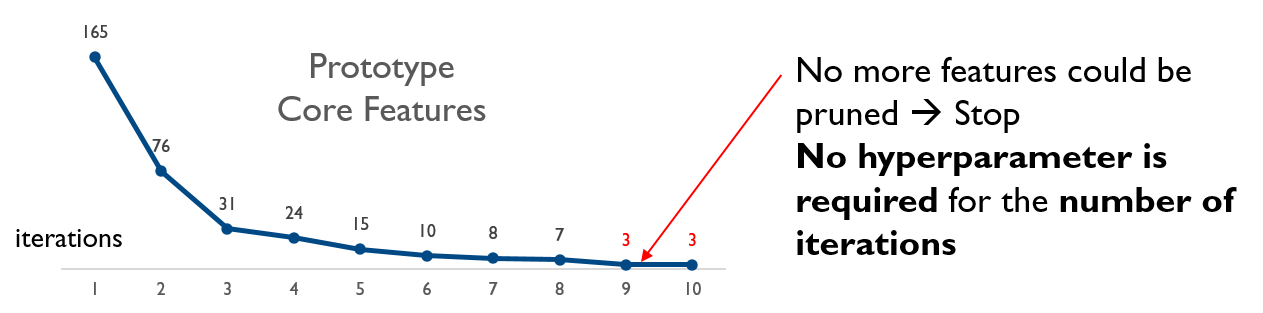
Natural Condition for Stopping Iterarions
No more features could be pruned --> Stop. No hyperparameter is required for the number of iterations.
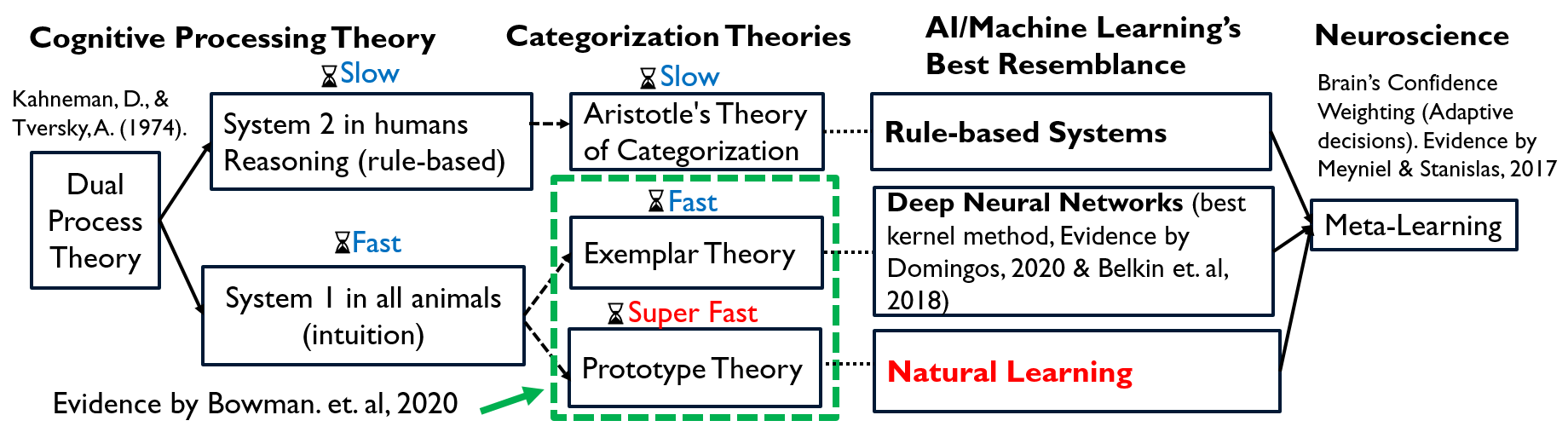
Natural Leaning emulates Brain's System 1's superfast categorization
Natural Leaning emulates Brain's System 1's superfast categorization according to Dual Process Theory and evidence found by Caitlin R., Takako Iwashita, and Dagmar Zeithamova..
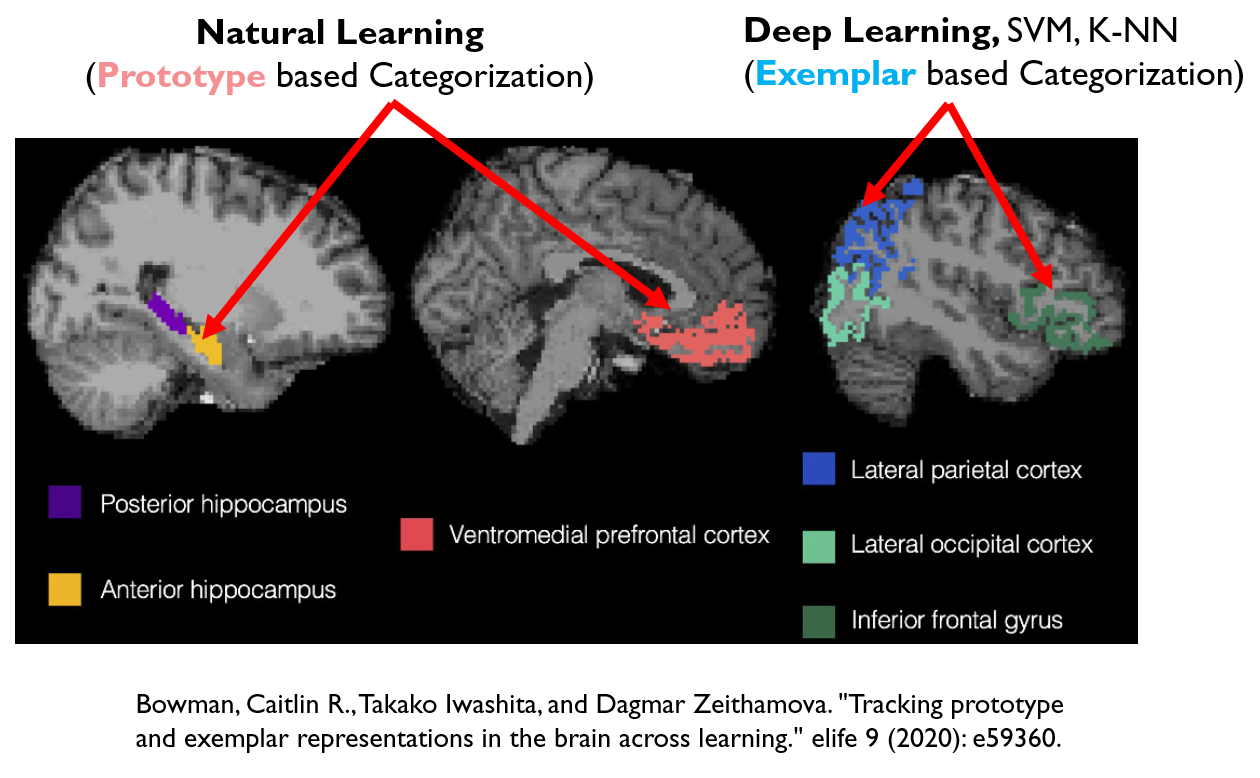
Brain uses both examplar-based and Prototype-based categorization
See Evidence by Bowman, Caitlin R., Takako Iwashita, and Dagmar Zeithamova. "Tracking prototype and exemplar representations in the brain across learning." elife 9 (2020): e59360.
Applications
Natural Learning relies on two primary assumptions: firstly, that there are single ideal prototypes within the training dataset, and secondly, that there are noisy labels. When these assumptions are met, Natural Learning achieves perfect predictions comparable to black-box models. These conditions are often observed in datasets concerning human-centric domains such as healthcare, finance, and criminal justice.
Healthcare
In medical diagnosis and treatment recommendation systems, interpretability ensures that doctors and patients can understand and trust the AI's recommendations. It helps in explaining why a particular diagnosis or treatment plan was suggested, enabling better decision-making.
Finance
In banking and finance, interpretable AI models are necessary for risk assessment, fraud detection, and loan approval processes. Regulatory bodies often require explanations for automated decisions, making interpretability crucial for compliance.
Criminal Justice
In predictive policing and recidivism prediction, interpretable AI models are essential for ensuring fairness and accountability in decision-making, as well as for maintaining public trust in law enforcement..
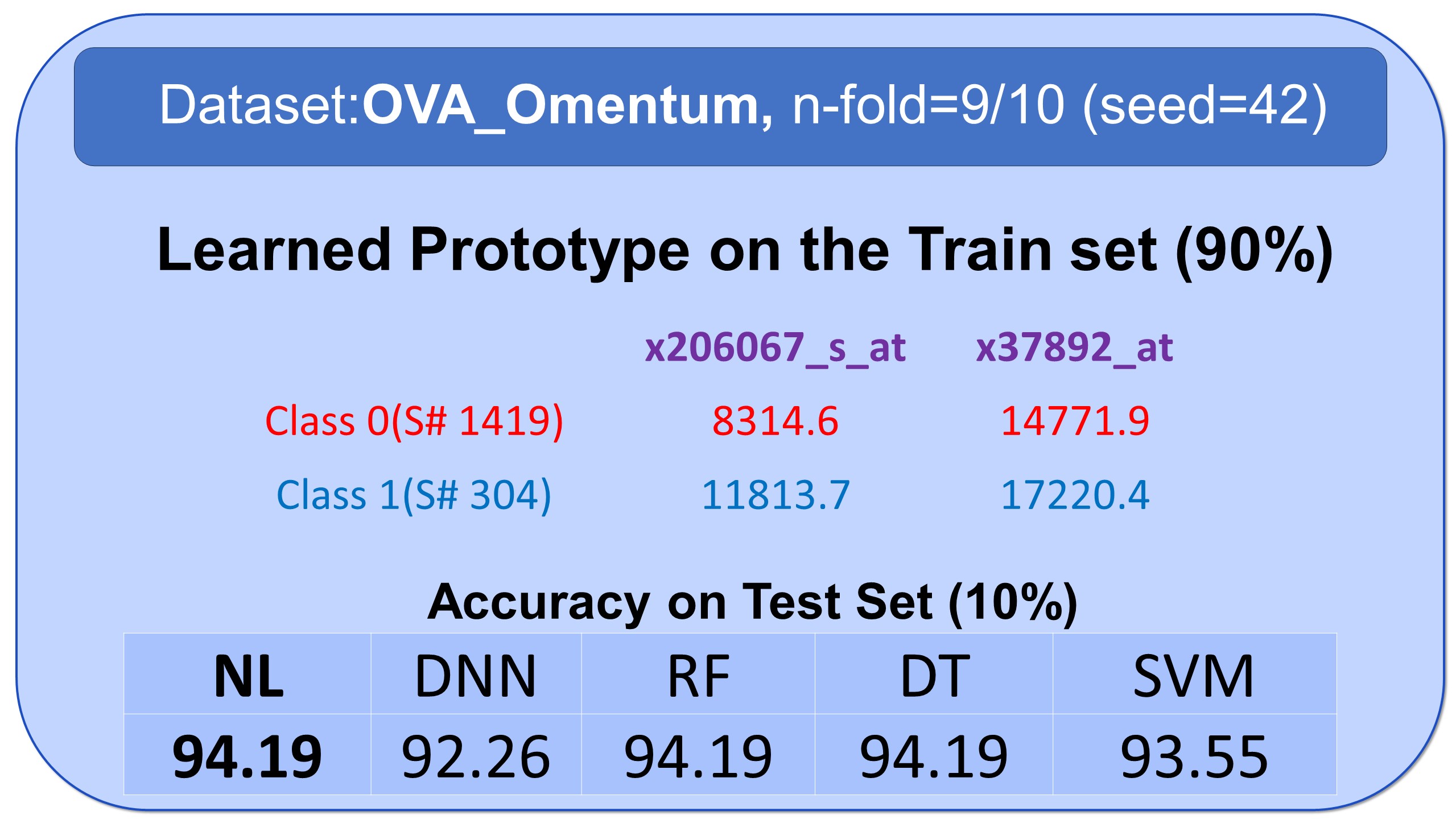
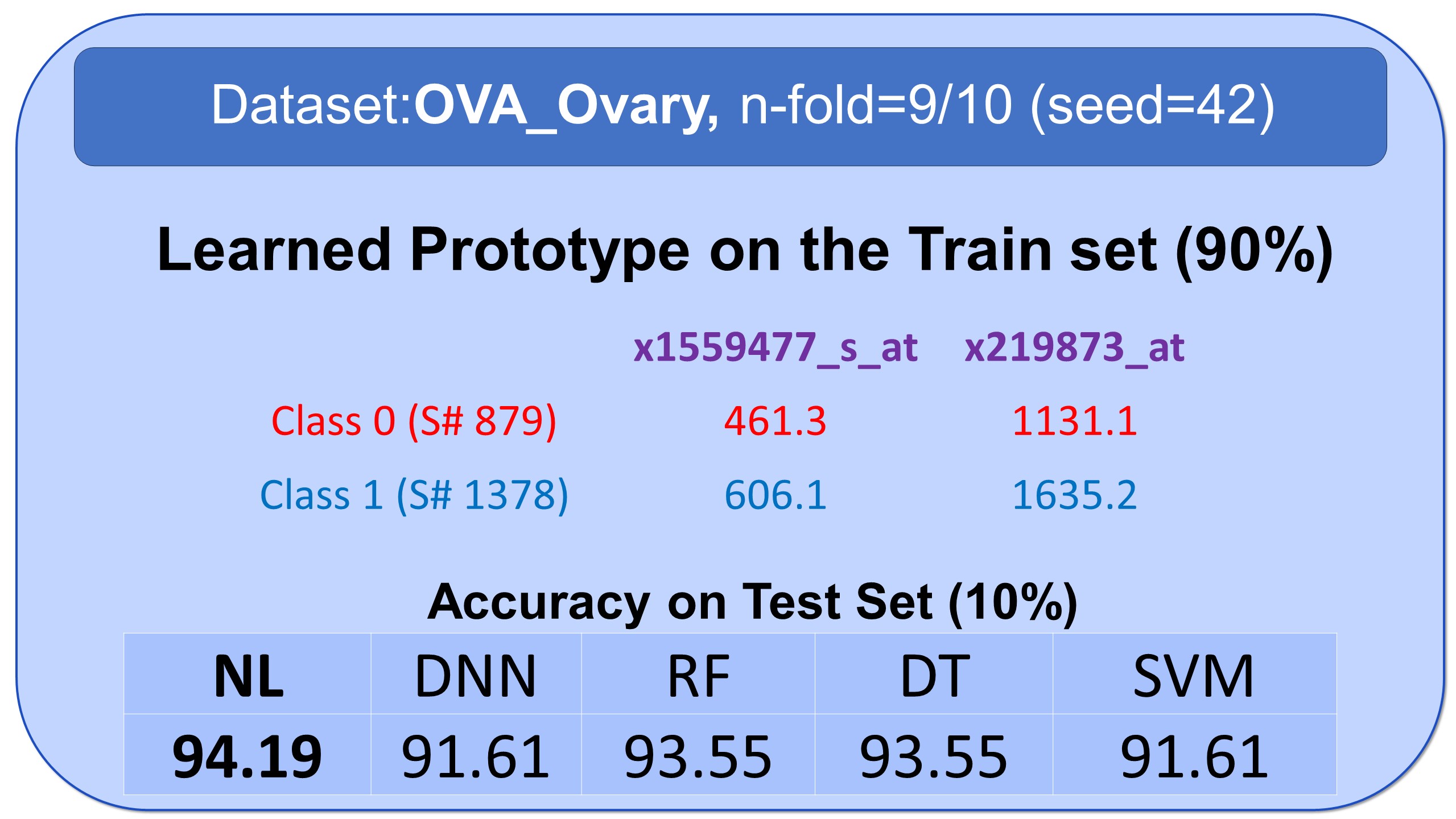
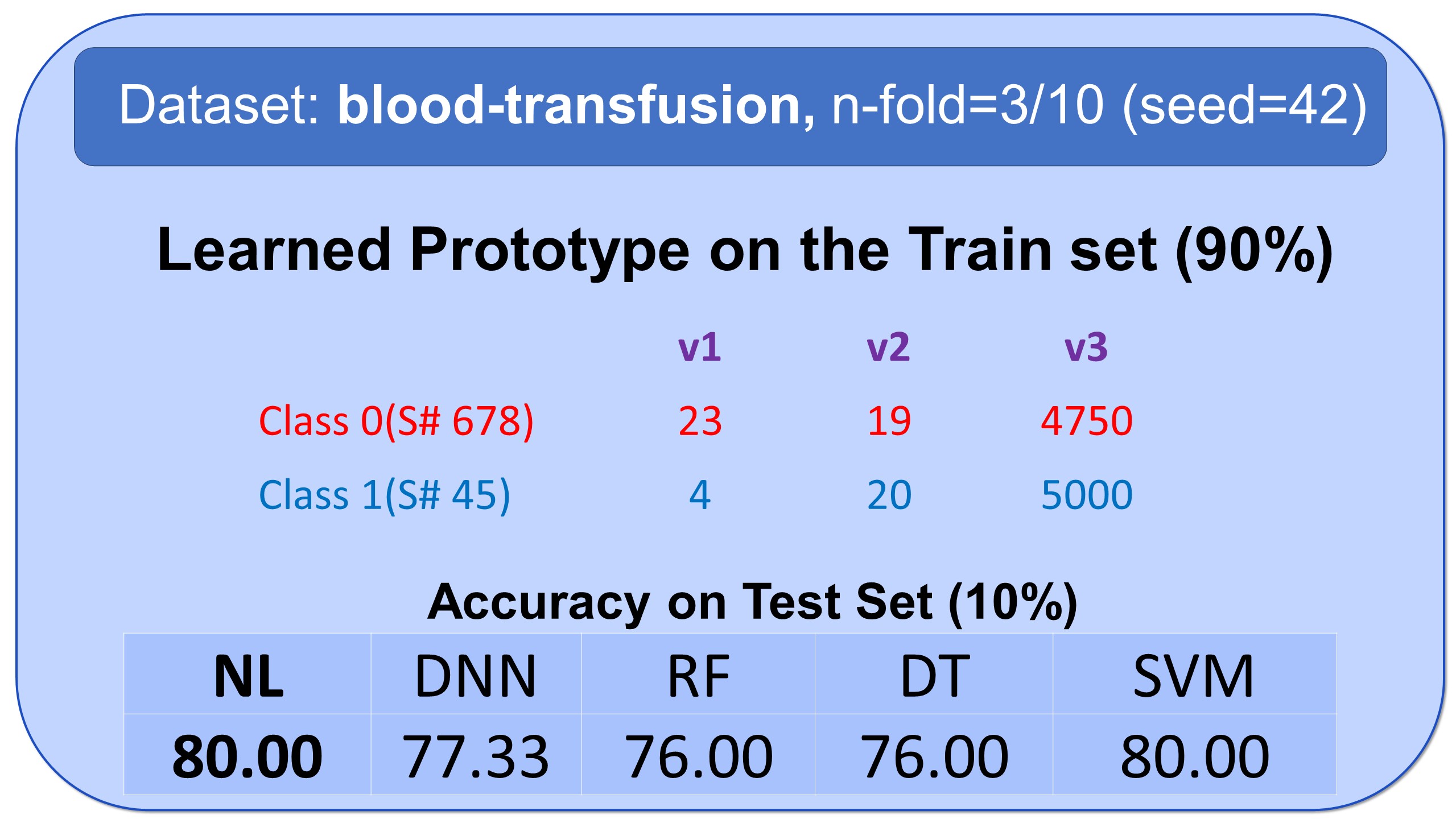
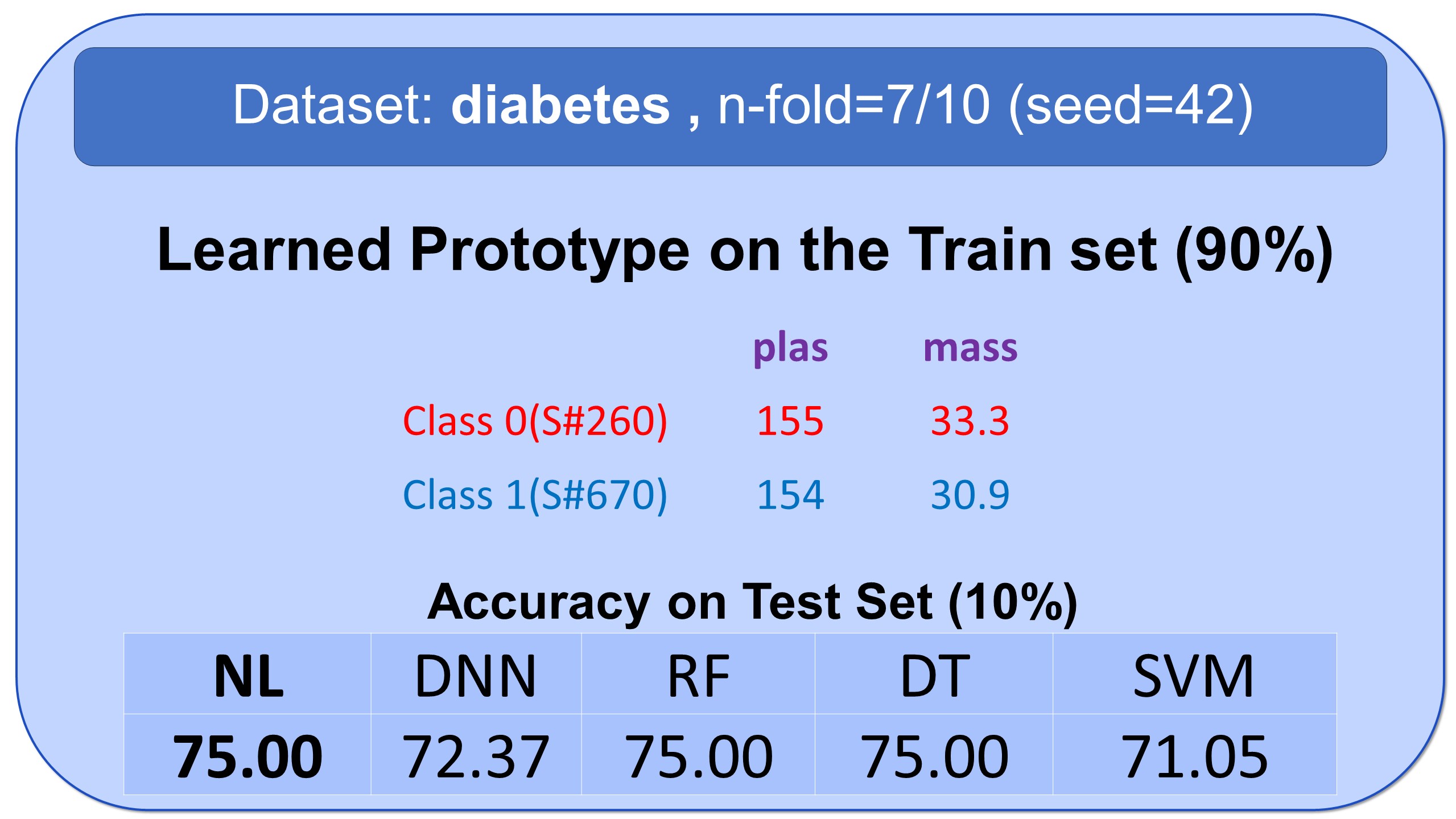
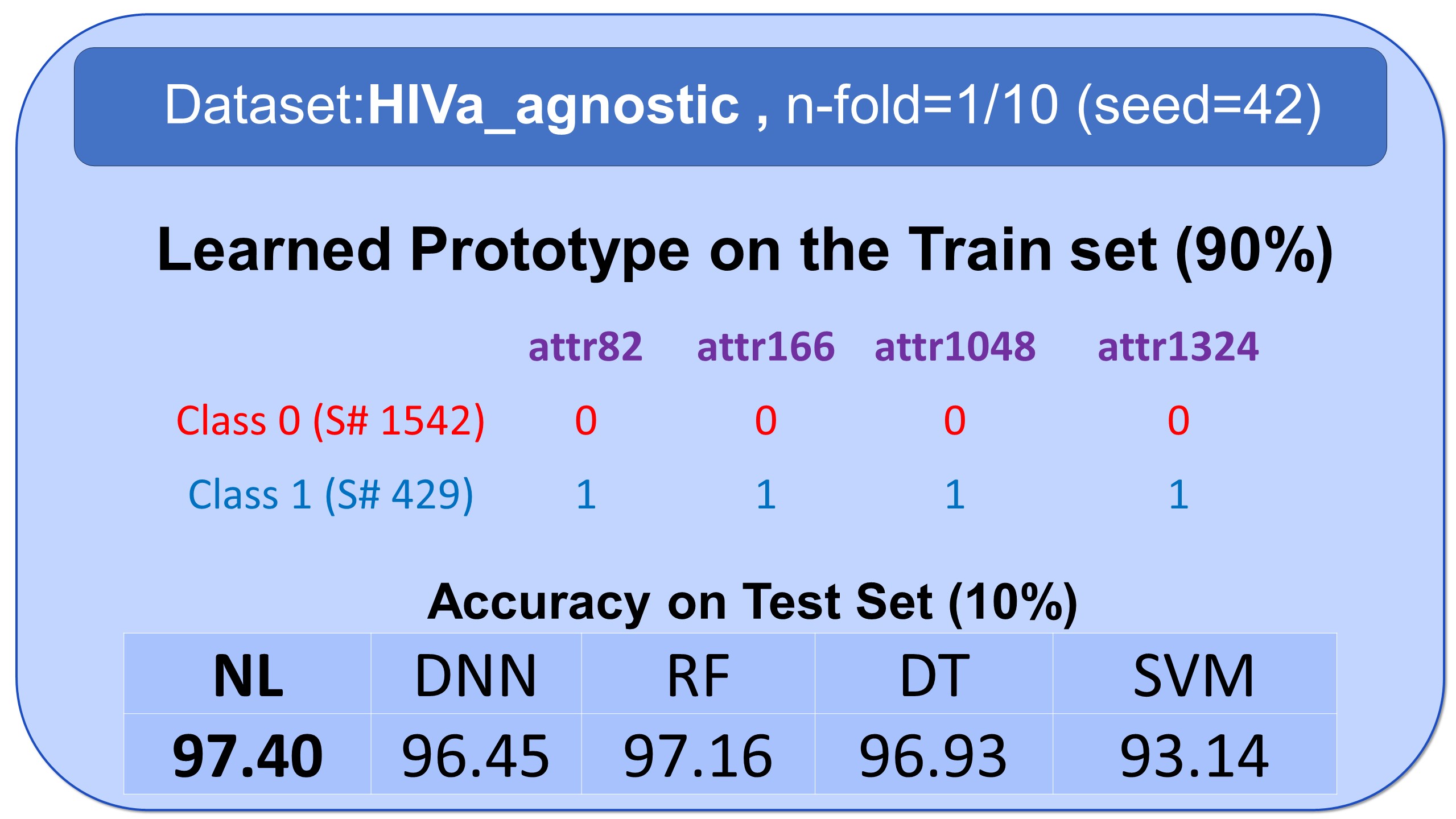
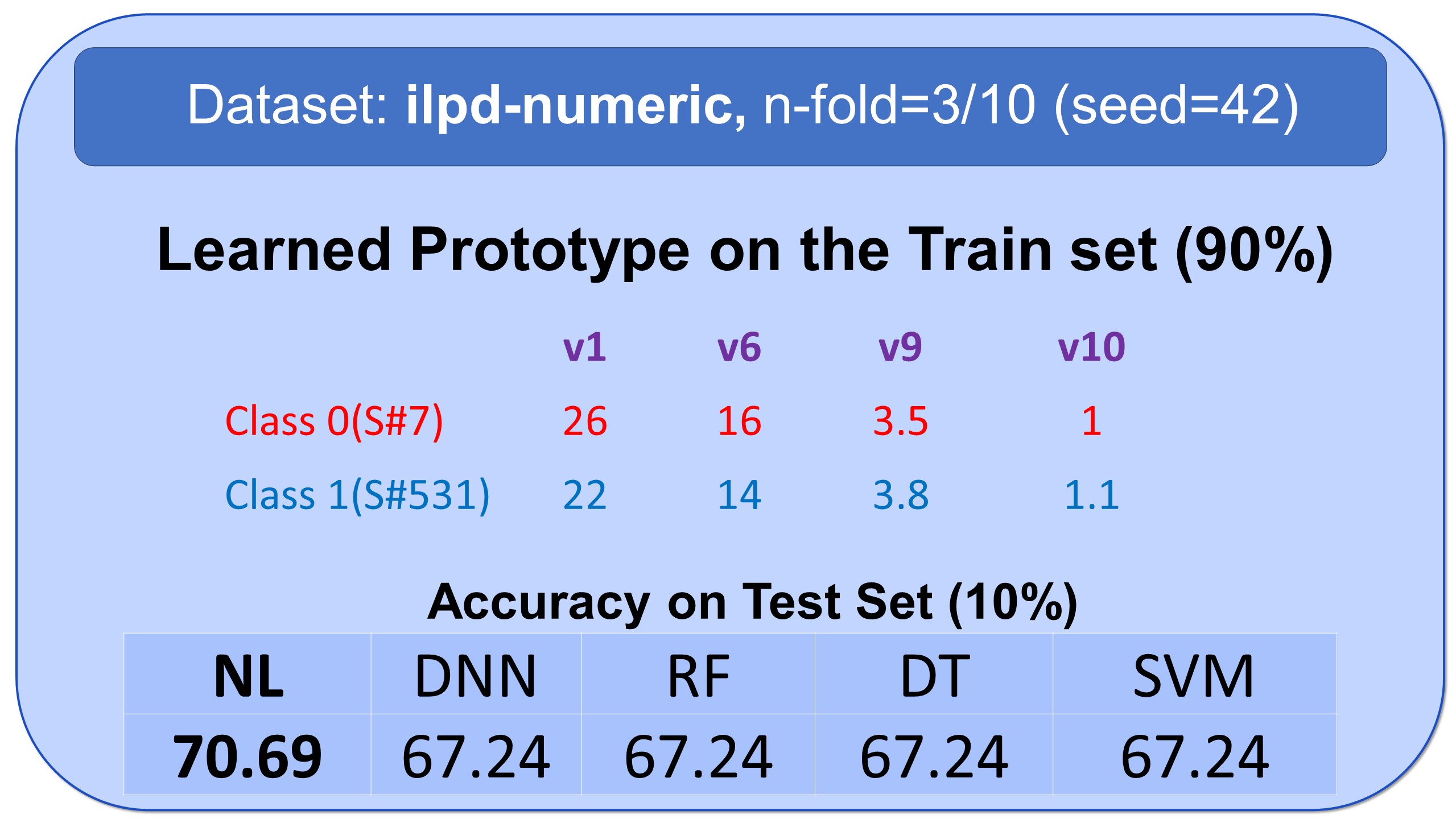
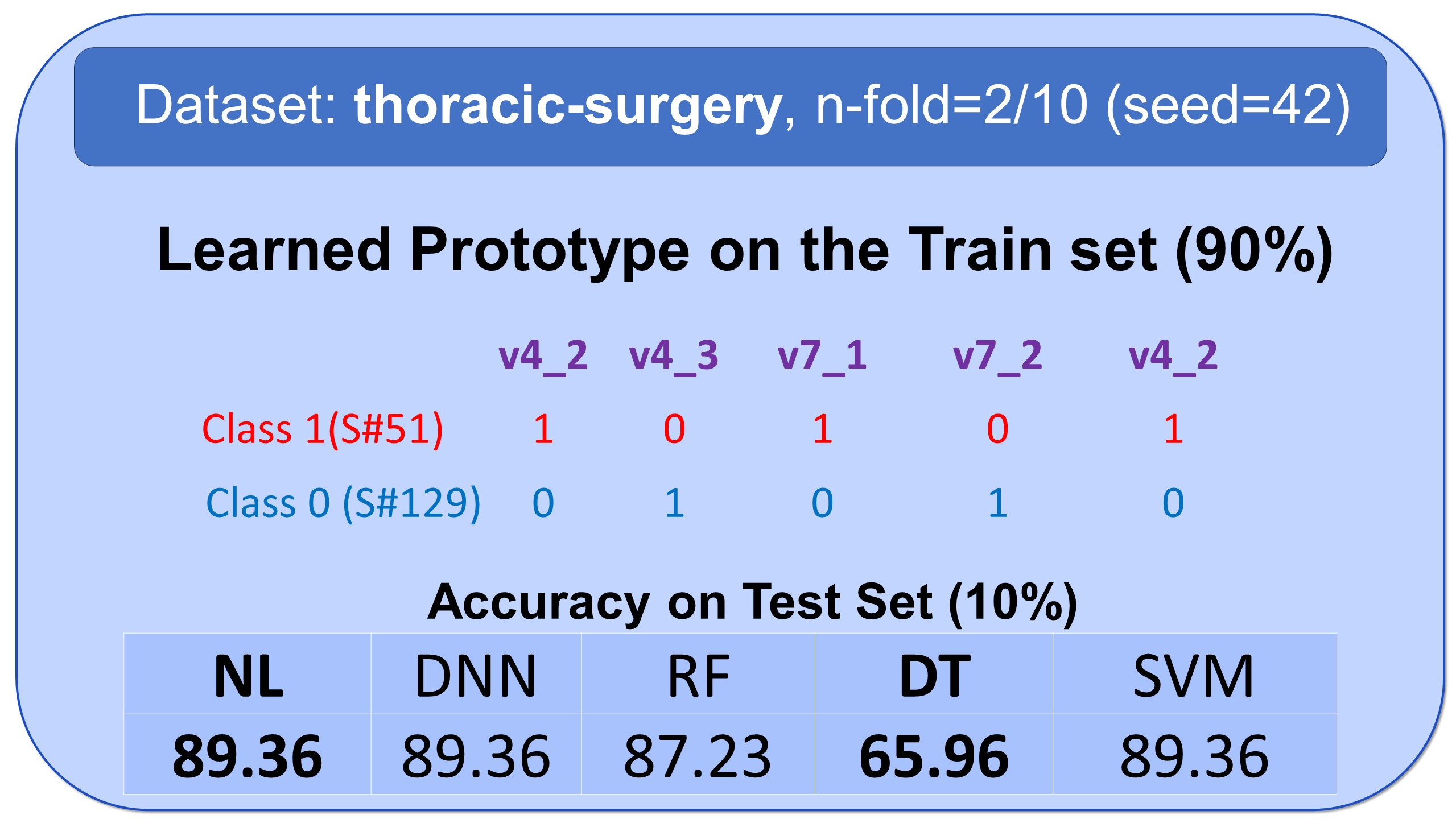
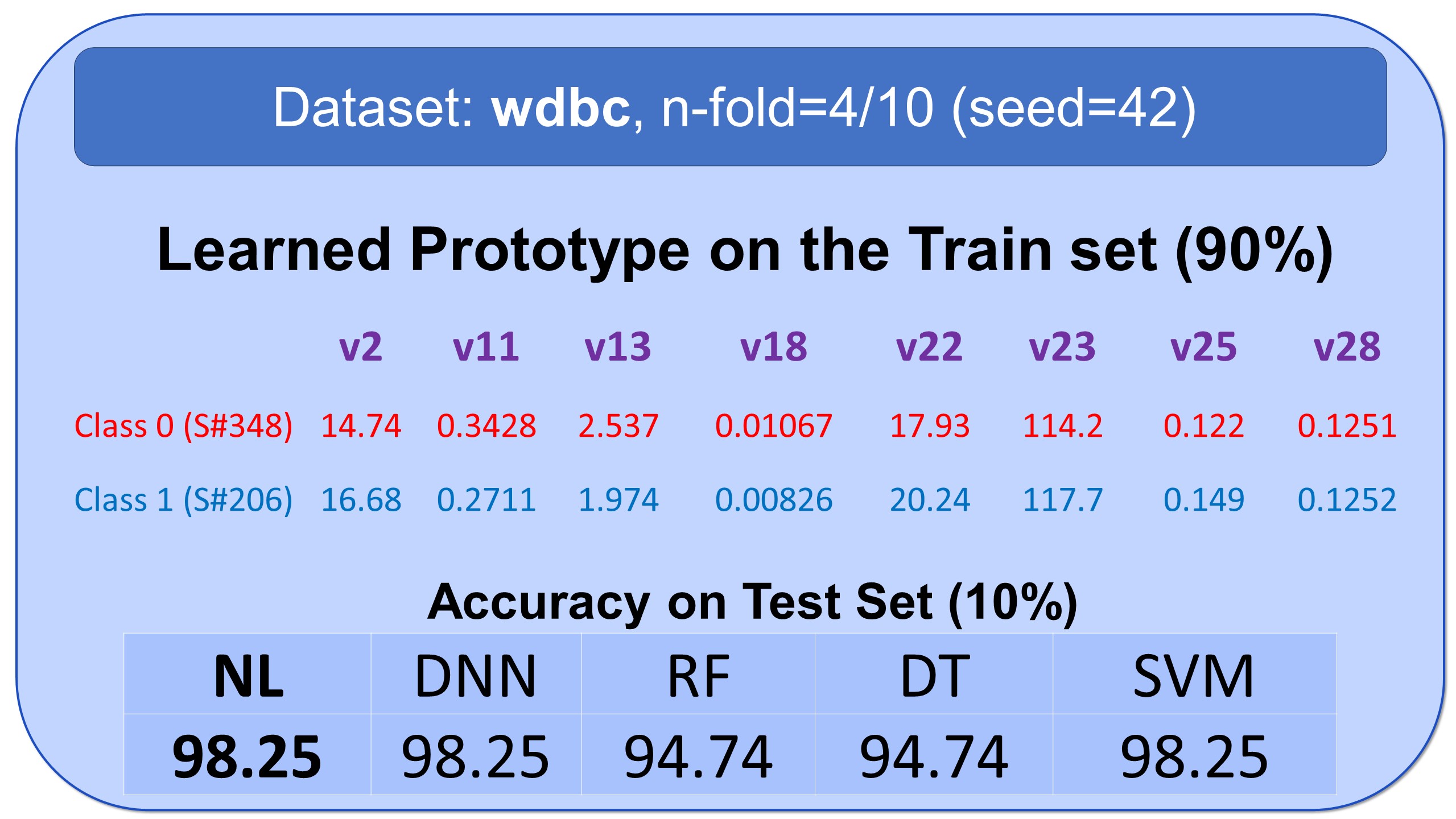
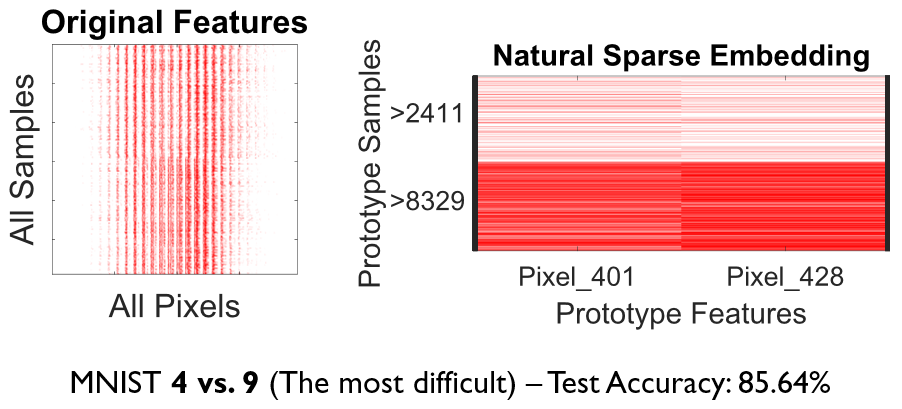
Examples of Prototypes Discovered by Natural Learning
Here, you see some examples of learned prototypes by Natural Learning. As you can see, the models of 9 datasets are so simple and small that they can be shown in half-page. All the results are reproducible. All models are built by seed=42. Regarding the train/test split, download the data from openml.org and use stratified sampling with an n-fold label in front of the names of datasets and seed=42. The models can also be verified manually. If the new sample is closer to the prototype of class 0 compared to the prototype of class 1, it will be labeled 0; otherwise, it will be labeled as 1.- All
- High-dimensional Data
- Low-dimensional Data
Paper
Hadi Fanaee-T Natural Learning. arXiv:2404.05903.Slides
Citation Details:
@article{fanaee2024natural,
title={Natural Learning},
author={Fanaee-T, Hadi},
journal={arXiv preprint arXiv:2404.05903},
year={2024}
}